
How I built PersonaBot as a production system with staged routing, hybrid retrieval and reranking, bounded retries, SSE streaming, and weekly eval gates with automatic chunk cleanup.
Most portfolio assistants fail in the same place. They can answer broad questions, but they break on specific ones. They also make it hard to tell when they are wrong.
I built PersonaBot to avoid that. The project is a retrieval-first system with explicit routing, confidence gates, source-linked answers, and an evaluation loop that runs in production workflows.
System goals and constraintsh2
The design started with practical constraints.
- Answers must be grounded in indexed sources.
- The route for each request should be predictable and debuggable.
- Latency should stay stable under free tier limits.
- Every stage should emit enough data for offline analysis.
That is why the project is structured as a staged pipeline rather than one large model call.
Runtime architectureh2
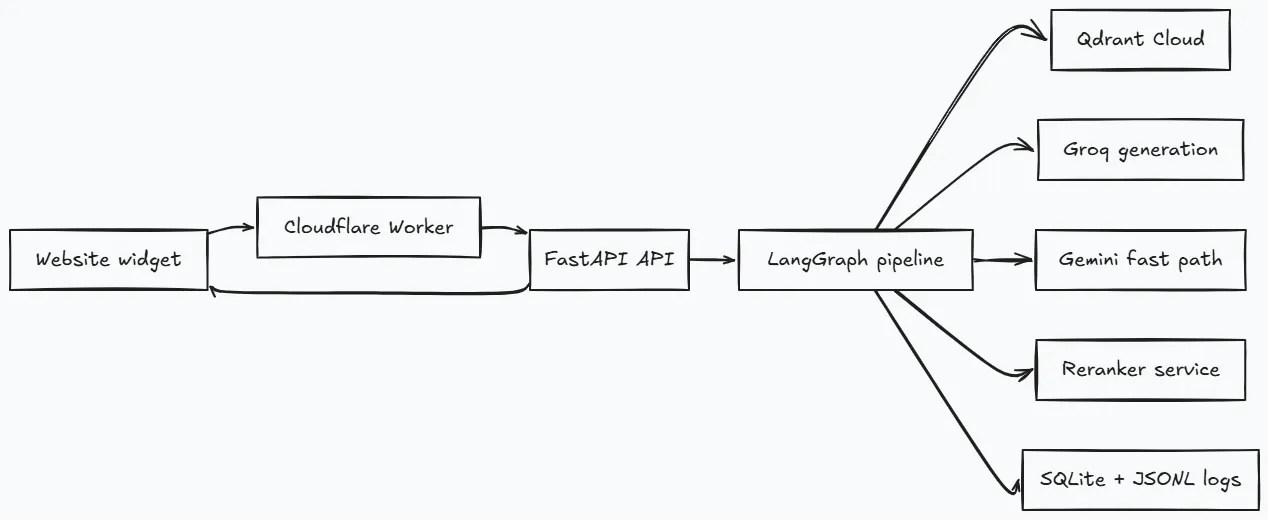
Each layer has a narrow responsibility.
- The Worker handles edge origin checks and coarse rate limiting.
- FastAPI owns auth, SSE streaming, and service wiring at startup.
- LangGraph controls routing with typed state transitions.
- Retrieval and generation services stay stateless and replaceable.
Startup wiring in backend/app/main.py is also important. Shared clients are initialized once in lifespan. They are not recreated per request. That removes a lot of avoidable latency variance.
Ingestion and indexingh2
The ingestion pipeline does more than chunk and embed.
- Parses blog posts, projects, PDF resume content, and public README sources.
- Chunks content by heading and tags each chunk as
leaf. - Extracts keyword payload fields for exact entity filtering.
- Stores dense and sparse vectors on the same Qdrant point.
- Adds
question_proxypoints for retrieval recall. - Builds RAPTOR summary nodes as a separate stage.
for chunk in chunks: chunk["metadata"]["chunk_type"] = "leaf" chunk["metadata"]["keywords"] = _extract_keywords(chunk["text"])
dense_embeddings = await embedder.embed(contextualised_texts, is_query=False)sparse_embeddings = sparse_encoder.encode([c["text"].lower() for c in chunks])leaf_uuids = store.upsert_chunks(chunks, dense_embeddings, sparse_embeddings)Dense vectors use BAAI/bge-small-en-v1.5. Sparse vectors use BM25 through FastEmbed. This combination helps with both semantic questions and exact name matching.
In GitHub ingestion mode, the collection can be force recreated to avoid stale artifacts from renamed or deleted content.
Request lifecycle stage by stageh2
The request path is explicit in the graph.
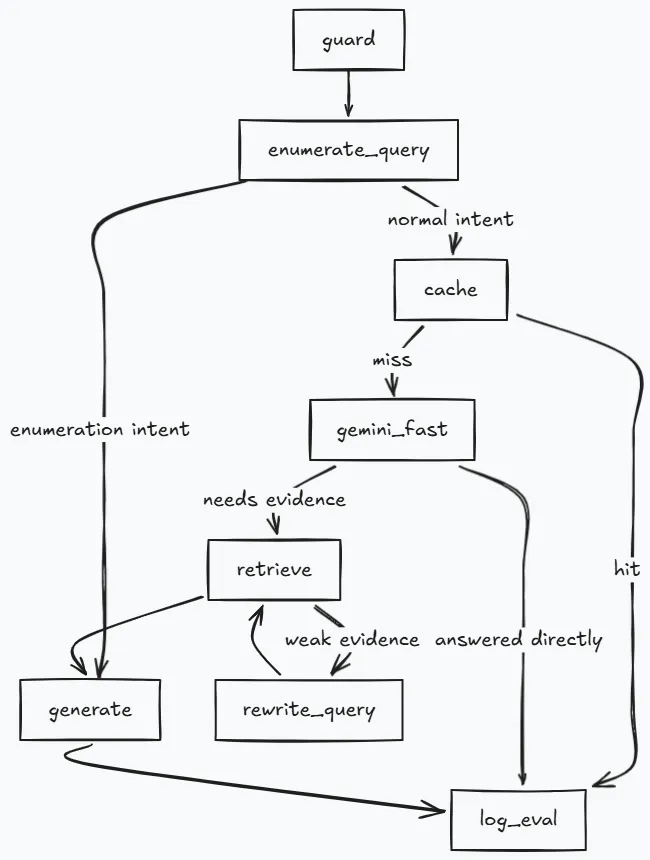
Stage 1. Guard and sanitizationh3
The pipeline sanitizes input first, then redacts PII patterns, then runs scope classification.
The classifier path is DistilBERT when artifacts exist. It falls back to regex rules when model artifacts are absent. The threshold is 0.70 with tokenizer max_length=128.
inputs = self._tokenizer(text, return_tensors="pt", truncation=True, padding=True, max_length=128)is_in_scope = in_scope_prob >= 0.70Stage 2. Enumeration query branchh3
List intent is handled before cache and before retrieval embeddings.
If the query asks for a complete list, the node scrolls Qdrant by payload filter and returns a deduplicated, title-level set. This avoids partial lists that can happen with similarity top-k retrieval.
Stage 3. Semantic cacheh3
Cache lookup happens before expensive retrieval and generation.
Configured values in backend/app/core/config.py are below.
SEMANTIC_CACHE_SIZE: int = 512SEMANTIC_CACHE_TTL_SECONDS: int = 3600SEMANTIC_CACHE_SIMILARITY_THRESHOLD: float = 0.92The cache also stores query embeddings in state so the retrieve node can reuse them and avoid duplicate embed calls.
Stage 4. Gemini fast path and query preparationh3
Gemini can answer trivial conversational queries directly. Non trivial and entity specific portfolio queries route to full RAG.
At request entry, two best-effort tasks are started in parallel.
- Decontextualize follow-up phrasing into a standalone query.
- Expand query forms for canonical names and related terms.
Budgets are short so they do not slow first token.
_DECONTEXT_TIMEOUT_SECONDS: float = 0.35_EXPANSION_TIMEOUT_SECONDS: float = 0.60_SSE_HEARTBEAT_SECONDS: float = 10.0Stage 5. Hybrid retrieval and rerankingh3
Retrieve combines three candidate streams.
- Dense vector search.
- Sparse BM25 search.
- Keyword payload filter search.
Then it fuses ranks with RRF and expands sibling chunks by doc_id before reranking.
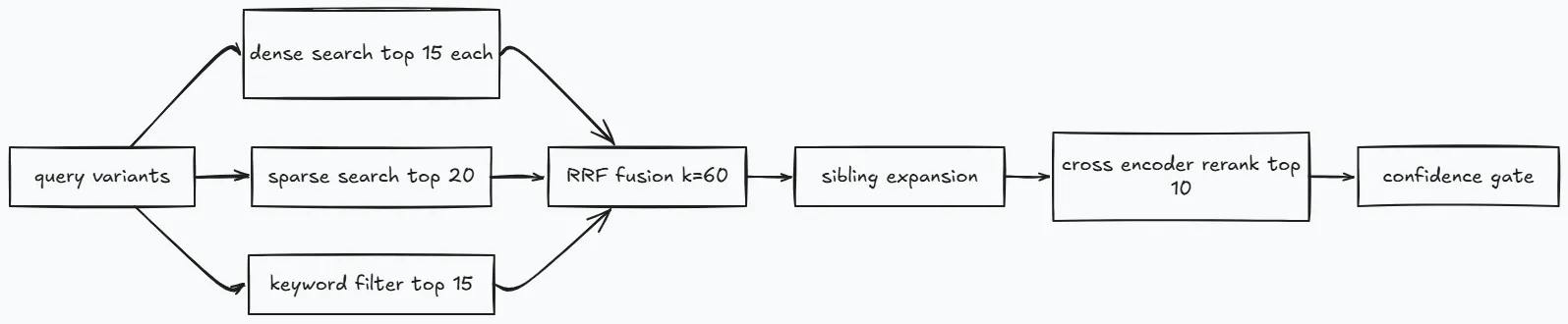
Core gate constants in backend/app/pipeline/nodes/retrieve.py.
_MIN_TOP_SCORE: float = -3.5_MIN_RESCUE_SCORE: float = -6.0_CRAG_LOW_CONFIDENCE_SCORE: float = -1.5_RRF_K: int = 60_SIBLING_EXPAND_TOP_N: int = 10_SIBLING_FETCH_LIMIT: int = 20_SIBLING_TOTAL_CAP: int = 15Reranker service calls are retried once on transient errors.
@retry( stop=stop_after_attempt(2), wait=wait_exponential(multiplier=0.4, min=0.4, max=1.2), retry=retry_if_exception_type((httpx.TimeoutException, httpx.HTTPError)), reraise=True,)async def _remote_call() -> tuple[list[int], list[float]]: async with httpx.AsyncClient(timeout=60.0) as client: ...Diversity caps are applied after rerank so one long document does not dominate the final context window.
Stage 6. Rewrite retry (CRAG style)h3
When retrieval is weak, the pipeline rewrites and retries instead of generating immediately.
The graph allows one retry for all meaningful queries and can allow a second retry for portfolio relevant noun queries. Retry count is tracked in state to keep the loop bounded.
Stage 7. Generation and citation handlingh3
Generation uses Groq models selected by complexity.
- Default model is
llama-3.1-8b-instant. - Large model is
llama-3.3-70b-versatile.
A shared TPM bucket prevents hard rate-limit failures by downgrading large model calls when usage in the current 60 second window passes the configured threshold.
class TpmBucket: _WINDOW_SECONDS: int = 60 _DOWNGRADE_THRESHOLD: int = 12_000Response handling in generate.py is strict.
- Stream tokens.
- Strip
<think>traces. - Normalize and reindex citations.
- Deduplicate source cards by URL identity.
- Trigger low-trust fallback behavior when needed.
Stage 8. Streaming contract and follow-upsh3
The API streams typed SSE events such as status, reading, sources, thinking, token, follow_ups, and final done.
Follow-up questions are generated after the main answer stream finishes. This keeps answer latency stable.
Stage 9. Logging and interaction schemah3
Every path writes to SQLite through log_eval.
Logged fields include query, answer, reranked chunk IDs, rerank scores, latency, path label, critic scores, enumeration flag, and retrieval diagnostics such as sibling expansion count.
That schema is what powers later evaluation and data prep workflows.
Security and reliabilityh2
Security is layered at edge, API, and pipeline level.
| Layer | Control | Verified behavior |
|---|---|---|
| Edge | Cloudflare Worker | origin controls plus 30 req/min/IP global limit |
| Edge audio | Cloudflare Worker | 10 req/min/IP for /transcribe |
| API | slowapi limiter | 20 req/min on chat endpoint |
| Auth | JWT validation | bearer token required on protected routes |
| Input | sanitizer + guard | sanitize, redact, classify before retrieval/generation |
if (entry.count > 30) { return new Response(JSON.stringify({ error: 'Rate limit exceeded. Try again in a minute.' }), { status: 429 })}
if (url.pathname.startsWith('/transcribe') && audioEntry.count > 10) { return new Response(JSON.stringify({ error: 'Audio rate limit exceeded. Try again in a minute.' }), { status: 429 })}Reliability controls are also explicit.
- SSE heartbeat every 10 seconds to keep long responses alive through proxies.
- Qdrant keepalive loop with a six day interval to avoid idle expiry patterns.
- Bounded timeouts around expansion and decontext tasks.
- Retry wrappers around remote model calls that can fail transiently.
Evaluation and improvement looph2
Production quality is treated as an engineering loop, not a one-time benchmark.
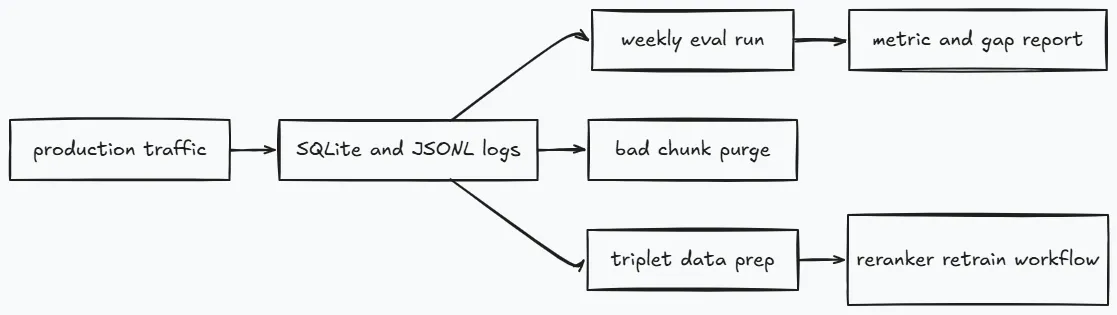
The offline evaluator in eval/run_eval.py runs golden questions against the live API endpoint and tracks both retrieval and answer metrics.
Regression thresholds are defined in code.
faithfulness >= 0.75answer_relevancy >= 0.70
The weekly workflow can run with or without RAGAS scoring. Operational checks still run when RAGAS is disabled.
Self purge runs in the same weekly loop using scripts/purge_bad_chunks.py.
- Candidate document appears at least 5 times as top chunk.
- Max top rerank score is at most
-2.5. - No positive feedback exists for those interactions.
Reranker data prep runs in a separate workflow and requires at least 100 new triplets by default before pushing dataset updates.
How to build a similar systemh2
If you want to build this kind of assistant yourself, this order is the most practical.
- Start with ingestion and reliable metadata fields.
- Build deterministic routing before tuning prompts.
- Add hybrid retrieval before trying larger generation models.
- Add citation post-processing and source filtering before polishing UI.
- Add logs with stable schemas early.
- Add eval and purge automation before calling it production.
A lot of teams reverse this order. They spend time on generation style before retrieval quality is stable. That usually slows progress because debugging stays ambiguous.
Design choices that paid offh2
Explicit routing instead of one big prompth3
I split the pipeline into nodes (guard, cache, fast path, retrieve, rewrite, generate) so behavior stayed inspectable. It was easier to debug because each failure had a clear location.
Hybrid retrieval before model scalingh3
Dense search alone missed exact entities, and keyword search alone missed intent. Running dense, sparse BM25, and payload filters together gave better recall, then reranking cleaned up precision.
Retries with hard limitsh3
Rewrite-and-retry improved weak retrieval cases, but only with strict retry caps. That kept latency predictable and stopped pathological loops.
Quality gates in the weekly looph3
Offline eval plus chunk-purge scripts turned quality into a maintenance task, not a one-off benchmark. If relevance or faithfulness drifts, it shows up quickly.
Engineering details that matteredh2
These were small decisions that had outsized impact in practice.
- Shared clients are initialized once in FastAPI lifespan, which reduced per-request setup overhead and latency variance.
- A semantic cache with threshold
0.92and TTL3600removed repeat work on common queries. - The TPM bucket in
llm_client.pydowngrades large-model calls when usage crosses12_000tokens per minute. - SSE heartbeat (
10s) plus bounded decontext and expansion timeouts kept long responses stable behind proxies.
Further readingh2
- LangGraph - Graph-based state machine for deterministic LLM pipelines.
- FastAPI lifespan events - Lifecycle hooks for shared client initialization and cleanup.
- Hybrid Search with Dense and Sparse Vectors - Combining semantic and keyword retrieval in one pipeline.
- Reciprocal Rank Fusion - Rank fusion algorithm for combining multiple retrieval signals.
- CRAG: Corrective Retrieval Augmented Generation - Rewrite-and-retry pattern for weak retrieval recovery.
- RAGAS: Retrieval-Augmented Generation Assessment - Metrics framework for retrieval and generation quality.
- Server-Sent Events (SSE) - Streaming protocol for real-time token and status delivery.
Live demo: darshanchheda.com/chat